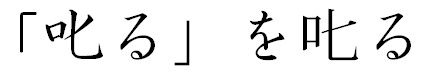「またまた訳の分からんタイトルだ」とおっしゃらず、上の二つの「しかる」の字をよくご覧いただきたい。微妙に異なっているのがお分かりだろうか。現代日本で使われている「叱る」の字体
1)には、大別して二とおりある。
①
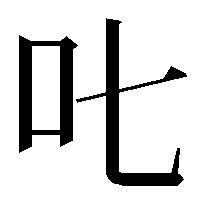
:表題の後の字。右側は「七」(漢数字の「しち」)。
②
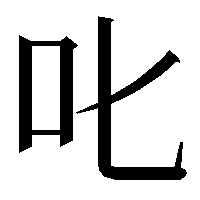
:表題の前の字。右側は「
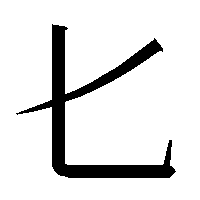
」(音カで、「化」の古文)
ほんのわずかな違いに見えるかもしれないが、4画目を左から右へ書くのと右上から左下に払うのとでは、大きな違いがあるといえる。また、「ほかの字と区別できなくなるのでなければ、細部の形にこだわらなくてもよい」という考え方もあるが、①と②の場合は、康煕字典などで別字として扱われているのである。
本来、「しかる」という字としてどちらが正しいかは、容易に理解できる。「
」は形声文字で、右側は音を示す声符なので、音シツを表す「七」を含むもの、すなわち①が正しい。「説文解字」でも、「訶也」と「しかる」の類義語を挙げたうえ、「口に従い七声」とする。小篆も、
の右側と七とはほぼ同形に書かれている。
「康煕字典」では、①について、説文解字を引用し、他に「尊客の前で狗(いぬ)を
らず」などの用例を載せている。また②については、音カで「口を開いたさま」とし、全く別の字として扱っている。
「しかる」の字は常用漢字表には2010年の改訂の際に追加されたが、表内の字体も①となっている。また、それ以前、まだこの字が表外漢字だった2000年に、国語審議会から答申された「表外漢字字体表」に掲げられた「印刷標準字体」にも、①の字体が選ばれており、この点では何の問題もない。
しかし現実には、印刷物はさておき、ウェブや会社の書類などでは、②が使われているケースが大半のようである
2)。その原因は日本工業規格(JIS)にある。
試みに、wordなどのワープロソフトやスマホで、「しかる」と打って変換していただきたい。多分②の方の字体が表示されるだろう。パソコンだと、さらに変換すると①の字体が候補に出る場合があるが、「環境依存文字(unicord)」と注記されている
3)。
②の字体がJIS第1水準の規格票にある例示字体で、JISでは標準的な字となっているといえる。①の字体は第3水準にあり、ユニコードの「CJK統合漢字拡張B」に対応するシステムでなければ使えない字となっている。
つまり、正しい字体であり常用漢字表にも採用されている字体がJISでは冷遇されているわけである。その原因を探ってみる。
JISX0208の附属書7「(参考)区点位置詳説」の叱字の欄に、規格票の印字字形の変更経過が載せられている。それによると、1978年の第1次規格第1刷では
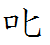
に近い字体(以下「③の字体」という)であり、第2刷から第4刷が②の字体、第4刷の正誤票で①の字体になったのは良いが、第7刷以降再び②の字体になって現在に至っている。
附属書にはさらに説明があり、「③及び②は、①とは別字とされている。」「字書典拠(新字源、大漢和辞典)は①の字体であり、一方、③及び②の字体は、字書では別字(音カ)であるとされている。」「しかし、実際には"しかる"の字としてフォント・活字に実現例が多く見られ、筆記形でも両様に書かれることがある。」と書かれている。
どういうことだろう。字書典拠から①が正しく、②は別字だとわかっていながら、現実に②が(
間違って!)使われることが多いため、②を規格票に掲げる例示字体としたということのようだ。そのために、フォント作成者は当然、第1水準の例示字体に倣ってフォントを作り、間違いが拡散されてしまったわけである。
先に述べたように、常用漢字表に掲げられているのは明らかに①の字体である。
ただし、同表の「(付) 字体についての解説>第1 明朝体のデザインについて>4 特定の字種に適用されるデザイン差について」 に両字体が掲載され、①と②の違いはデザインの違いであって字体の違いではないとされている。
また、特にこの字種については、「①と②は本来別字とされるが,その使用実態から見て,異体の関係にある同字と認めることができる。」という説明も付されている。
さらに、「第2 明朝体と筆写の楷書との関係について」において、筆写の場合は③も含めて「習慣の相違に基づく表現の差と見るべきもの」としている。
また、2000年答申の「印刷標準字体」には、②の字体が「デザイン差と位置付けられた別字形」として掲載されている。
筆者としてはこれらにも賛同しがたい。②の字体は明らかに①の写し間違いから発生したものであり、形声文字としての
の成り立ちからしてあり得ないものである。また、今後の学校教育などによって、時間はかかるだろうが十分矯正可能なものと思われるので、規範としては①のみを認めるべきではないか。
しかし、本表では①の字形であるので、JISよりは「まし」であると言える。
ここでまたJISに立ち返ると、JIS規格票の例示字体は常用漢字表にも印刷標準字体にも反していることになる
4)。「デザイン差」の字体があったとしても、規格票には標準的な字体を例示すべきことは当然である。まして、正誤表でいったん①の字形に直しておきながら、再び②の字体に戻すなんて、JISはいったい何を考えていたのか。
憤慨しながらなおも調査を進めた。
JISに「情報交換用漢字符号系」が定められたのは、1978年のJISC6226である。このときには第1・第2水準の漢字6349字が規定された。その後、1990年にはJISX0208に改正され、その後も何度かの改正を経て現在に至っている。
一方、2000年には、「拡張漢字集合」であるJISX0213が制定された。これは、X0208の文字に加えて、第3・第4水準の漢字を含む上位集合である。
「しかる」字についていえば、先に述べたように②が第1水準でX0208とX0213の双方に規定され、①は第3水準でX0213のみに規定されている。ただし第1水準の叱字は、包摂規準により、右側が七でも匕でもヒでも同じコードを割り当てられることになっている。そのうち、例示字体として②を選んで掲げているということである。
つまり、X0208のままでも①の字は使えたが、X0213を定めるにあたり、①の字体専用のコードを第3水準に設けたということになる。これは2000年の国語審議会答申で①の字体が採用されたことによるものと思われるが、常用漢字の字体を尊重するなら、第1水準の例示字体を①に変えれば済んだ話である。
しかしこのころ、①の字体にとって不利な状況があらわになっていた。「国際的」に見て、①の字体は主流派ではなかったのである。
国際的な文字コードの規格として、ユニコード(Unicode)がある。全世界の文字に統一的コードを与えて誰もが利用できるようにしようと考えて作られたものである。この一部に「CJK統合漢字」という集合がある(1992年制定)。中国、日本、韓国の頭文字をとった名であるが、台湾や香港の繁体字、更にはベトナムでかつて使われていた字体も含まれている。
ユニコードは多くの文字にコードを与えるが、JISとは異なり、例示字体を掲げることはない。各国(地域)が、ユニコードの各符号に、自国の国内規格を連動させるのである。

上の図はユニコードの"U+53F1"の符号位置にある各国の字体である。左から、中国本土、香港、台湾、日本、韓国、ベトナムの国内規格の字体が掲載されているが、ご覧のとおり、①を採用しているのはベトナムだけであり、繁体字を使う香港や台湾でも、康煕字典に反して②を使っている。理由は不明だが、①の影は薄い
5)。
その後、ユニコードは規定する文字を増やしていき、2001年には「CJK統合漢字拡張B」という集合が規定された。前年にJISX0213に規定された①の字体は、この時に"U+20B9F"という5桁のコードを与えられたが、統合漢字の本体に入らなかったので、「環境依存」の字となってしまった。
前述のとおり、JISX0213でも、①の字体は第1水準の字に包摂されることになっており、第1水準のコードで①のフォントを作っても良いのである。つまり、例示字体を①に戻し、フォント作成者に①のフォントを推奨し、普及すれば常用漢字表の「
」のコードを第1水準のものに替えればよい。そうすれば、常用漢字もJIS漢字も正しい字体となり、情報通信にも何の支障もなくなるのである。中国本土の簡体字、香港・台湾の繁体字と、既にかなりの漢字の字体が異なったものとなっている現在、他国の状況を考慮する必要もないだろう。
ちなみに、2010年の常用漢字表改定に向けた、文化庁文化審議会国語分科会漢字小委員会(第39回、2010年1月29日)の議事録によると、この日の審議の場で「
」の字体も議題となり、「携帯電話等では印刷標準字体が出ないので、常用漢字としてJISの字体(②)を採用するか、②を許容字体とすることにしてほしい」という意見が出ている(10ページ)
6)。前述の常用漢字表(付)の「第1」は、このような意見を受けて追加されたもののようである。しかし、JISの字体の方を①に替えよ、という意見が出ていないのは不審である。文化審議会は文部科学省の所管、JISは経済産業省の所管なので、他省庁の縄張りを侵さないように、という配慮を委員に求めていたとしたら残念である。
最後に、本稿を執筆する動機となった、ある「実害」について述べる。
ある会報に漢字に関するクイズが載っていた
7)。その一つが
「口」に2画足してできる漢字は?(ただし「日」は使わない)
という問題で、常用漢字で15個の漢字を書けというものだ。
筆者は苦労して(一部カンニングもして)15個の字を挙げたが、答え合わせをしたところ、筆者が挙げた「
」という字が解答にないのである(替わりに筆者が見逃した「号」が挙がっていた)。
実は、当然ではあるが、文化庁HPの常用漢字表(PDF版)の「
」の字は、第3水準のコードでないと検索できない。検索窓に「環境依存文字でない②」を入力しても、ヒットしないのだ。筆者が検索したときは(付)にある②の字がヒットしたが、出題者は恐らく、文化庁HPからコピーして作成された別の常用漢字リストを使って、②の文字を入力して検索し、ヒットしないので常用漢字ではないと判断したものと思われる。印刷画像では些細な違いではあるが、文字コードの世界では全く別の字と認識されてしまうのである。
このように、文字に関する我が国の2大基準である常用漢字表とJISに食い違いがあると、思わぬところで問題を起こす恐れがある。JISには早急な改定をお願いしたい。
【2020.8.10.追記】本稿掲載後、筆者のユニコードに関する認識に誤りがあることが分かりましたので、改訂いたしました。旧稿をお読みいただいた方々にお詫びいたします。
注1)後述するように、常用漢字表の「(付) 字体についての解説」には、①と②の違いはデザインの違いであって字体の違いではないと記載されている。しかし筆者は、これらの字はもともと別の漢字であるので、両者の違いは字体の違いであると考え、以下の文章でも「字体」という語を使用する。 戻る
注2)印刷物については、標準字体の功績か、①の字体に従っているものが多いようだが、用例が少ないのであまり確認できない。筆者が確認できたのは、朝日新聞大阪本社版2016年9月3日付beの1面、新潮文庫の梅原猛著「葬られた王朝」230ページ、などである。一方、ウェブでは、Googleで両字を検索してみると、②が816万件ヒットしたのに対し、①の環境依存文字ではわずか1500件で、5000分の1以下である(2016年9月25日調査)。後述する、JIS第1水準にあることの影響力がこれで分かる。
 |
| 読売新聞の叱字画像 |
【2017.10追記】その後も注意していると、2017年7月4日の各紙朝刊に「
」字が掲載されているのを見つけた。5大紙を見比べると、朝日・毎日・産経・日経は①の字体だが、読売だけ②の字体を使っていることがわかった(いずれも大阪本社版)。
ちなみに記事の内容は、東京都議選の惨敗を受けた自民党・安倍晋三総裁のコメント「厳しい
咤と受け止め、深刻に反省したい」を伝えるものである。安倍総裁に感謝したい。
戻る
注3) Microsoft Office IME 2010の場合。フォントによっては判別しがたいものもあるが、ほとんどすべてのフォントで、普通に変換した場合は②の字形が表示される。教科書体では(後述の字体③)と表示され、②とも違って右側は音ヒの字である(拙稿「同じ形で別の漢字・ヒと」参照)。①の字体を出すには環境依存文字を選択するが、対応していないフォントも多い。 戻る
注4)IMEで変換すると、候補漢字の表の隣に「標準辞書」が表示され、そこには①の字体は「印刷標準字体」、②は「デザイン差」と書かれている。これは2000年の国語審議会答申に基づくものだろうが、環境依存文字が標準字体であるという、誰が見てもおかしい事態を招いている。 戻る
注5)調べてみると、中国では、かなり古くからもっぱら②の字体が用いられてきたことが分かった。
日本では、「大漢和辞典」も「大言海」(新編)も「広辞苑」も、①の字体を採用している。しかし中国では、「大書源」に掲げる唐以降の書蹟11例のうち、唐・顔真卿の1例を除く10例が、②または③の字体で記されている。現代中国の辞書類も大半は②の字体である。
また、中国の字典サイト「漢典」で検索すると、①②の字形に対応した康煕字典の字がそれぞれ表示されるが、康煕字典の本文は入れ替わってしまっている。つまり①の字形の方に「開口貌」と出るのだ。台湾・中央研究院のサイト「古今文字資料庫」では、①②どちらで検索しても同じ②の字形が出る(楷書の場合。添付された「字號」の数字は異なるが)。このように、漢字の「本家」においても、字体に関する意識は高くないようである。 戻る
注6)現在の常用漢字の字体が携帯電話等で出ないケースとして、ほかに「 」「
」「 」「
」「 」がある。最近のパソコンであれば「環境依存文字」ながら使える字ではあるが、これらの字を携帯やスマホに送ると、「?」と表示される場合が多い。「頬」「填」「剥」はJISX0208にあるので、携帯等でも使える。この3組の字は異体字の関係にある字なので、「」と「叱」ほどの問題はないように見えるが、常用漢字の字体に忠実にパソコン等で作った文書が、携帯電話等では文字化けするという点では、同じ問題を抱えているといえる。
」がある。最近のパソコンであれば「環境依存文字」ながら使える字ではあるが、これらの字を携帯やスマホに送ると、「?」と表示される場合が多い。「頬」「填」「剥」はJISX0208にあるので、携帯等でも使える。この3組の字は異体字の関係にある字なので、「」と「叱」ほどの問題はないように見えるが、常用漢字の字体に忠実にパソコン等で作った文書が、携帯電話等では文字化けするという点では、同じ問題を抱えているといえる。
【2020.8.10.追記】 本稿を改訂するにあたり、確認のため再度パソコンから筆者のスマホにメールすると、「「」「」「」の4文字はいずれも正常に表示された。「」については、スマホで「ほほ」と打って変換することもできた。本稿を掲載した2016年にはできなかったはずだが、やはりICTの世界は日進月歩ということか。 戻る
注7)日本漢字能力検定協会発行「漢検生涯学習ネットワーク 会員通信」Vol.22 2016.8) 戻る
参考・引用資料
説文解字 後漢・許慎撰、100年:下記「説文解字注」より
説文解字注 清・段玉裁注、1815年:影印本第4次印刷 浙江古籍出版社 2010年
康煕字典(内府本) 清、1716年[東京大学東洋文化研究所所蔵]:PDF版 初版 パーソナルメディア 2011年
常用漢字表、表外漢字字体表 文化庁ウェブサイト
日本工業規格 日本工業標準調査会ウェブサイト
大書源 二玄社 2007年
文化庁文化審議会国語分科会漢字小委員会議事録 文化庁ウェブサイト
異体字の世界 最新版 3刷 小池和夫著、河出文庫 2016年
画像引用元(特記なきもの)
小篆 漢字古今字資料庫(台湾・中央研究院ウェブサイト)
康煕字典(内府本) 清、1716年[東京大学東洋文化研究所所蔵]:PDF版 初版 パーソナルメディア 2011年
明朝体の漢字 グリフウィキ(ウェブサイト)
CJK Unified Ideographs(Unicode, Inc. ウェブサイト)